Open Access
Open AccessEditor-in-Chief

Prof. Shaohua Wan
University of Electronic Science and Technology of China, China
eISSN
3029-2786
Publication Frequency
Quarterly (since 2025)
Indexing
All the publications will be archived by the PKP Preservation Network for long-term electronic preservation.
Authors are encouraged to self-archive the final version of their published articles into institutional repositories (such as those listed in the Directory of Open Access Repositories).
Authors are also encouraged to use the final PDF version published on the website of Academic Publishing.
Google Scholar
J-Gate
About the Publisher
Academic Publishing insists on taking academic exchange and publication as the main line, carrying out comprehensive management based on science and technology, and fully exploring excellent international publishing resources. Within 5 years, it will form a strategic framework and scale with science (S), technology (T), medicine (M), education (E), and humanities and arts (H) as the main publishing fields. Academic Publishing is headquartered in Singapore and based in Malaysia, with the United States and China providing the main scientific and academic resources. At the same time, it has established long-term good cooperative relations with other publishing companies, scientific research communities, and academic organizations in more than a dozen countries and regions. Academic Publishing uses English and Chinese as its main publishing languages, mainly publishing books, journals, and conference papers in print and online. The vast majority of publications follow the international open access policy, providing stable and long-term quality and professional publications. With the joint efforts of the expert team and our professional editorial team, our publications will gradually be indexed by international databases in stages to provide convenient and professional retrieval for various scholars. At the same time, manuscripts we accept will be subject to the peer review principle, and cutting-edge and innovative research articles will be preferentially accepted for peer reference and discussion. All kinds of our publications are welcome for peer to contribute, access, and download.
Volume Arrangement
2023
Featured Articles
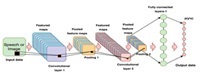
Deep learning (DL) techniques which implement deep neural networks became popular due to the increase of high-performance computing facilities. DL achieves higher power and flexibility due to its ability to process many features when it deals with unstructured data. DL algorithm passes the data through several layers; each layer is capable of extracting features progressively and passes it to the next layer. Initial layers extract low-level features, and succeeding layers combine features to form a complete representation. This research attempts to utilize DL techniques for identifying sounds. The development in DL models has extensively covered classification and verification of objects through images. However, there have not been any notable findings concerning identification and verification of the voice of an individual from different other individuals using DL techniques. Hence, the proposed research aims to develop DL techniques capable of isolating the voice of an individual from a group of other sounds and classify them based on the use of convolutional neural networks models AlexNet and ResNet, that are used in voice identification. We achieved the classification accuracy of ResNet and AlexNet model for the problem of voice identification is 97.2039 % and 65.95% respectively, in which ResNet model achieves the best result.
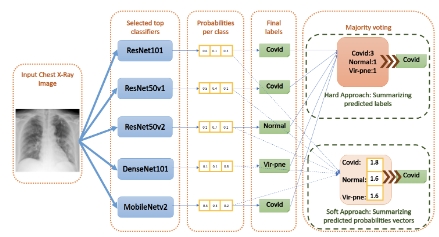
The integration of artificial intelligence (AI) has brought about a paradigm shift in the landscape of Neurosurgery and Neurology, revolutionizing various facets of healthcare. This article meticulously explores seven pivotal dimensions where AI has made a substantial impact, reshaping the contours of patient care, diagnostics, and treatment modalities. AI’s exceptional precision in deciphering intricate medical imaging data expedites accurate diagnoses of neurological conditions. Harnessing patient-specific data and genetic information, AI facilitates the formulation of highly personalized treatment plans, promising more efficacious therapeutic interventions. The deployment of AI-powered robotic systems in neurosurgical procedures not only ensures surgical precision but also introduces remote capabilities, mitigating the potential for human error. Machine learning models, a core component of AI, play a crucial role in predicting disease progression, optimizing resource allocation, and elevating the overall quality of patient care. Wearable devices integrated with AI provide continuous monitoring of neurological parameters, empowering early intervention strategies for chronic conditions. AI’s prowess extends to drug discovery by scrutinizing extensive datasets, offering the prospect of groundbreaking therapies for neurological disorders. The realm of patient engagement witnesses a transformative impact through AI-driven chatbots and virtual assistants, fostering increased adherence to treatment plans. Looking ahead, the horizon of AI in Neurosurgery and Neurology holds promises of heightened personalization, augmented decision-making, early intervention, and the emergence of innovative treatment modalities. This narrative is one of optimism and collaboration, depicting a synergistic partnership between AI and healthcare professionals to propel the field forward and significantly enhance the lives of individuals grappling with neurological challenges. This article provides an encompassing view of AI’s transformative influence in Neurosurgery and Neurology, highlighting its potential to redefine the landscape of patient care and outcomes.
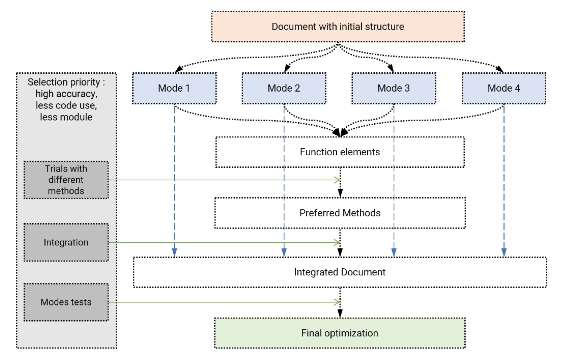
This paper begins with a theoretical exploration of the rise of large language models (LLMs) in Human-Computer Interaction (HCI), their impact on user experience (HX) and related challenges. It then discusses the benefits of Human-Centered Design (HCD) principles and the possibility of their application within LLMs, subsequently deriving six specific HCD guidelines for LLMs. Following this, a preliminary experiment is presented as an example to demonstrate how HCD principles can be employed to enhance user experience within GPT by using a single document input to GPT’s Knowledge base as new knowledge resource to control the interactions between GPT and users, aiming to meet the diverse needs of hypothetical software learners as much as possible. The experimental results demonstrate the effect of different elements’ forms and organizational methods in the document, as well as GPT’s relevant configurations, on the interaction effectiveness between GPT and software learners. A series of trials are conducted to explore better methods to realize text and image displaying, and jump action. Two template documents are compared in the aspects of the performances of the four interaction modes. Through continuous optimization, an improved version of the document was obtained to serve as a template for future use and research.
In this study, the author proposes and details a workflow for the spatial-temporal demarcation of urban areal features in 8 cities of Tamilnadu, India. During the inception phase, functional requirements and non-functional parameters are analyzed and designed, within a suitable pixel area and object-oriented derived paradigm. Land use categories are defined from OpenStreetMap (OSM) related works with the scope of conducting climate change, using multispectral sensors onboard Landsat series. Furthermore, we augment the bands dataset with Spatially Invariant Feature Transform (SIFT), Normalized Difference Vegetation Index (NDVI), Normalized Difference Built-Up Index (NDBI), Leaf Area Index (LAI), and Texture base indices, as a means of spatially integrating auto-covariance to stationarity patterns. In doing so, change detection can be pursuit by scaling up the segmentation of regional/zonal boundaries in a multi-dimensional environment, with the aid of Wide Area Networks (WAN) cluster computers such as the BEOWULF/Google Earth Engine clusters. GeoAnalytical measures are analyzed in the design of local and zonal spatial models (GRID, RASTER, DEM, IMAGE COLLECTION). Finally, multi variate geostatistical works are ensued for precision and recall in predictive data analytics. The author proposes reusing machine learning tools (filtering by attribute-based indexing in PaaS clouds) for pattern recognition and visualization of features and feature collection.
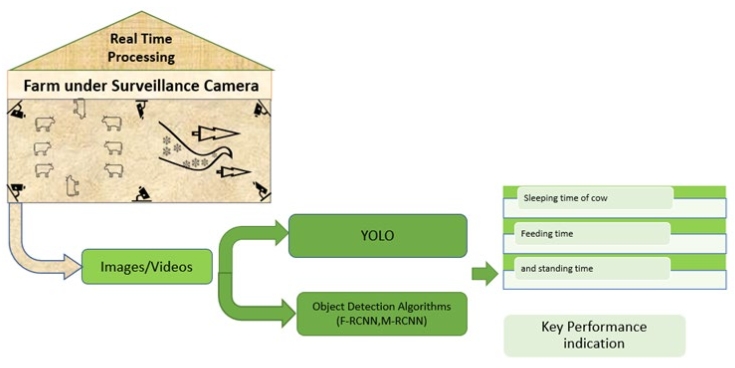
Nowadays, it is a challenge for farmers to produce healthier food for the world population and save land resources. Recently, the integration of computer vision technology in field and crop production ushered in a new era of innovation and efficiency. Computer vision, a subfield of artificial intelligence, leverages image and video analysis to extract meaningful information from visual data. In agriculture, this technology is being utilized for tasks ranging from disease detection and yield prediction to animal health monitoring and quality control. By employing various imaging techniques, such as drones, satellites, and specialized cameras, computer vision systems are able to assess the health and growth of crops and livestock with unprecedented accuracy. The review is divided into two parts: Livestock and Crop Production giving the overview of the application of computer vision applications within agriculture, highlighting its role in optimizing farming practices and enhancing agricultural productivity.