A comparison of cepstral and spectral features using recurrent neural network for spoken language identification
Abstract
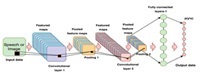
Spoken language identification is the process of confirming labels regarding the language of an audio slice regardless of various features such as length, ambiance, duration, topic or message, age, gender, region, emotions, etc. Language identification systems are of great significance in the domain of natural language processing, more specifically multi-lingual machine translation, language recognition, and automatic routing of voice calls to particular nodes speaking or knowing a particular language. In his paper, we are comparing results based on various cepstral and spectral feature techniques such as Mel-frequency Cepstral Coefficients (MFCC), Relative spectral-perceptual linear prediction coefficients (RASTA-PLP), and spectral features (roll-off, flatness, centroid, bandwidth, and contrast) in the process of spoken language identification using Recurrent Neural Network-Long Short Term Memory (RNN-LSTM) as a procedure of sequence learning. The system or model has been implemented in six different languages, which contain Ladakhi and the five official languages of Jammu and Kashmir (Union Territory). The dataset used in experimentation consists of TV audio recordings for Kashmiri, Urdu, Dogri, and Ladakhi languages. It also consists of standard corpora IIIT-H and VoxForge containing English and Hindi audio data. Pre-processing of the dataset is done by slicing different types of noise with the use of the Spectral Noise Gate (SNG) and then slicing into audio bursts of 5 seconds duration. The performance is evaluated using standard metrics like F1 score, recall, precision, and accuracy. The experimental results showed that using spectral features, MFCC and RASTA-PLP achieved an average accuracy of 76%, 83%, and 78%, respectively. Therefore, MFCC proved to be the most convenient feature to be exploited in language identification using a recurrent neural network long short-term memory classifier.
Copyright (c) 2024 Irshad Ahmad Thukroo, Rumaan Bashir, Kaiser Javeed Giri

This work is licensed under a Creative Commons Attribution 4.0 International License.
References
[1]China Bhanja C, Laskar MA, Laskar RH. Modelling multi-level prosody and spectral features using deep neural network for an automatic tonal and non-tonal pre-classification-based Indian language identification system. Language Resources and Evaluation. 2021, 55(3): 689-730. doi: 10.1007/s10579-020-09527-z
[2]Lee HS, Tsao Y, Jeng SK, et al. Subspace-Based Representation and Learning for Phonotactic Spoken Language Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2020, 28: 3065-3079. doi: 10.1109/taslp.2020.3037457
[3]Chandak C, Raeesy Z, Rastrow A, et al. Streaming language identification using combination of acoustic representations and ASR hypotheses. arXiv. 2020. doi.org/10.48550/arXiv.2006.00703
[4]Gemmeke JF, Van Hamme H, Cranen B, et al. Compressive Sensing for Missing Data Imputation in Noise Robust Speech Recognition. IEEE Journal of Selected Topics in Signal Processing. 2010, 4(2): 272-287. doi: 10.1109/jstsp.2009.2039171
[5]Wang P, Tan K, Wang DL. Bridging the Gap Between Monaural Speech Enhancement and Recognition With Distortion-Independent Acoustic Modeling. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2020, 28: 39-48. doi: 10.1109/taslp.2019.2946789
[6]Albadr MAA, Tiun S, Ayob M, et al. Mel-Frequency Cepstral Coefficient Features Based on Standard Deviation and Principal Component Analysis for Language Identification Systems. Cognitive Computation. 2021, 13(5): 1136-1153. doi: 10.1007/s12559-021-09914-w
[7]Biswas M, Rahaman S, Kundu S, et al. Spoken Language Identification of Indian Languages Using MFCC Features. Machine Learning for Intelligent Multimedia Analytics. Published online 2021: 249-272. doi: 10.1007/978-981-15-9492-2_12
[8]Wicaksana VS, S.Kom AZ. Spoken Language Identification on Local Language using MFCC, Random Forest, KNN, and GMM. International Journal of Advanced Computer Science and Applications. 2021, 12(5). doi: 10.14569/ijacsa.2021.0120548
[9]Athiyaa N, Jacob G. Spoken language identification system using MFCC features and gaussian mixture model for Tamil and Telugu Languages. International Research Journal of Engineering and Technology(IRJET). 2019, 6(4): 4243–4248.
[10]Das A, Guha S, Singh PK, et al. A Hybrid Meta-Heuristic Feature Selection Method for Identification of Indian Spoken Languages From Audio Signals. IEEE Access. 2020, 8: 181432-181449. doi: 10.1109/access.2020.3028241
[11]Das HS, Roy P. Bottleneck Feature-Based Hybrid Deep Autoencoder Approach for Indian Language Identification. Arabian Journal for Science and Engineering. 2020, 45(4): 3425-3436. doi: 10.1007/s13369-020-04430-9
[12]Qu D, Wang B, Wei X. Language identification using vector quantization. In: Proceedings of the 6th International Conference on Signal Processing; 26–30 August 2002; Beijing, China. 492–495. doi: 10.1109/ICOSP.2002.1181100
[13]Maity S, Kumar Vuppala A, Rao KS, et al. IITKGP-MLILSC speech database for language identification. 2012 National Conference on Communications (NCC). Published online February 2012. doi: 10.1109/ncc.2012.6176831
[14]Sarthak, Shukla S, Mittal G. Spoken Language Identification Using ConvNets. Ambient Intelligence. Published online 2019: 252-265. doi: 10.1007/978-3-030-34255-5_17
[15]Lopez-moreno I, Gonzalez-dominguez J, Plchot, D. Martinez O, et al. Google Inc ., New York, USA ATVS-Biometric Recognition Group, Universidad Autonoma de Madrid, Spain Brno University of Technology, Czech Republic Aragon Institute for Engineering Research (I3A), University of Zaragoza, Spain. 2014. pp. 0–4.
[16]Hermansky H, Morgan N. RASTA processing of speech. IEEE Transactions on Speech and Audio Processing. 1994, 2(4): 578-589. doi: 10.1109/89.326616
[17]Hermansky H, Morgan N, Bayya A, Kohn P. RASTA-PLP speech analysis technique. In: Proceedings of the ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing; 23–26 March 1992; San Francisco, CA, USA. pp. 121-124. doi: 10.1109/ICASSP.1992.225957
[18]Kingsbury BED, Morgan N. Recognizing reverberant speech with RASTA-PLP. In: Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing; 21–24 April 1997; Munich, Germany. pp. 1259–1262. doi: 10.1109/ICASSP.1997.596174
[19]Razia Sulthana A, Mathur A. A State of Art of Machine Learning Algorithms Applied Over Language Identification and Speech Recognition Models. International Virtual Conference on Industry 40. Published online 2021: 123-132. doi: 10.1007/978-981-16-1244-2_10
[20]Ghanghor N, Krishnamurthy P, Thavareesan S, et al. IIITK@DravidianLangTech-EACL2021: Offensive language identification and meme classification in Tamil, Malayalam and Kannada. In: Chakravarthi B, Priyadharshini R, Kumar MA, et al., Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages; 20 April 2021; Kyiv, Ukraine. Association for Computational Linguistics; 2021. pp. 222–229.
[21]Anusuya MA, Katti SK. Speech recognition by machine: A review. International Journal of Computer Science and Information Security. 2009. 6(3): 181–205.
[22]Schutte KT. Parts-Based Models and Local Features for Automatic Speech Recognition [PhD thesis]. Massachusetts Institute of Technology; 2009.
[23]Deshwal D, Sangwan P, Kumar D. Feature Extraction Methods in Language Identification: A Survey. Wireless Personal Communications. 2019, 107(4): 2071-2103. doi: 10.1007/s11277-019-06373-3
[24]Han W, Chan CF, Choy CS, Pun KP. An efficient MFCC extraction method in speech recognition. In: Proceedings of the 2006 IEEE International Symposium on Circuits and Systems (ISCAS); 21–24 May 2006; Kos, Greece. pp. 145–148. doi: 10.1109/ISCAS.2006.1692543
[25]Dewi Renanti M, Buono A, Ananta Kusuma W. Infant cries identification by using codebook as feature matching, and MFCC as feature extraction. Journal of Theoretical and Applied Information Technology. 2013, 56(3): 437–442.
[26]Trang H, Tran Hoang Loc, Huynh Bui Hoang Nam. Proposed combination of PCA and MFCC feature extraction in speech recognition system. 2014 International Conference on Advanced Technologies for Communications (ATC 2014). Published online October 2014. doi: 10.1109/atc.2014.7043477
[27]Ahmed AI, Chiverton JP, Ndzi DL, et al. Speaker recognition using PCA-based feature transformation. Speech Communication. 2019, 110: 33-46. doi: 10.1016/j.specom.2019.04.001
[28]Krishna SR, Rajeswara R. SVM based emotion recognition using spectral features and PCA. International Journal of Pure and Applied Mathematics. 2017, 114(9): 227–235.
[29]Sabab MdN, Chowdhury MAR, Nirjhor SMMI, et al. Bangla Speech Recognition Using 1D-CNN and LSTM with Different Dimension Reduction Techniques. Emerging Technologies in Computing. Published online 2020: 158-169. doi: 10.1007/978-3-030-60036-5_11
[30]Saleh MAM, Ibrahim NS, Ramli DA. Data reduction on MFCC features based on kernel PCA for speaker verification system. WALIA Journal. 2014, 30(S2): 56–62.
[31]Winursito A, Hidayat R, Bejo A. Improvement of MFCC feature extraction accuracy using PCA in Indonesian speech recognition. 2018 International Conference on Information and Communications Technology (ICOIACT). Published online March 2018. doi: 10.1109/icoiact.2018.8350748
[32]Mukherjee H, Obaidullah SM, Santosh KC, et al. A lazy learning-based language identification from speech using MFCC-2 features. International Journal of Machine Learning and Cybernetics. 2019, 11(1): 1-14. doi: 10.1007/s13042-019-00928-3
[33]Boussaid L, Hassine M. Arabic isolated word recognition system using hybrid feature extraction techniques and neural network. International Journal of Speech Technology. 2017, 21(1): 29-37. doi: 10.1007/s10772-017-9480-7
[34]Guha S, Das A, Singh PK, et al. Hybrid Feature Selection Method Based on Harmony Search and Naked Mole-Rat Algorithms for Spoken Language Identification From Audio Signals. IEEE Access. 2020, 8: 182868-182887. doi: 10.1109/access.2020.3028121
[35]Bashir R, Quadri S. Identification of Kashmiri script in a bilingual document image. 2013 IEEE Second International Conference on Image Information Processing (ICIIP-2013). Published online December 2013. doi: 10.1109/iciip.2013.6707658
[36]Thukroo IA, Bashir R. Spoken Language Identification System for Kashmiri and Related Languages Using Mel-Spectrograms and Deep Learning Approach. 2021 7th International Conference on Signal Processing and Communication (ICSC). Published online November 25, 2021. doi: 10.1109/icsc53193.2021.9673212
[37]van Keeken A. Understanding Records. A Field Guide to Recording Practice. Second Edition. By Jay Hodgson. New York: Bloomsbury, 2019. 233 pp. ISBN 978-1-5013-4237-0. Popular Music. 2021, 40(1): 172-174. doi: 10.1017/s0261143021000192
[38]Deshwal D, Sangwan P, Kumar D. A Language Identification System using Hybrid Features and Back-Propagation Neural Network. Applied Acoustics. 2020, 164: 107289. doi: 10.1016/j.apacoust.2020.107289
[39]Sharma G, Umapathy K, Krishnan S. Trends in audio signal feature extraction methods. Applied Acoustics. 2020, 158: 107020. doi: 10.1016/j.apacoust.2019.107020